
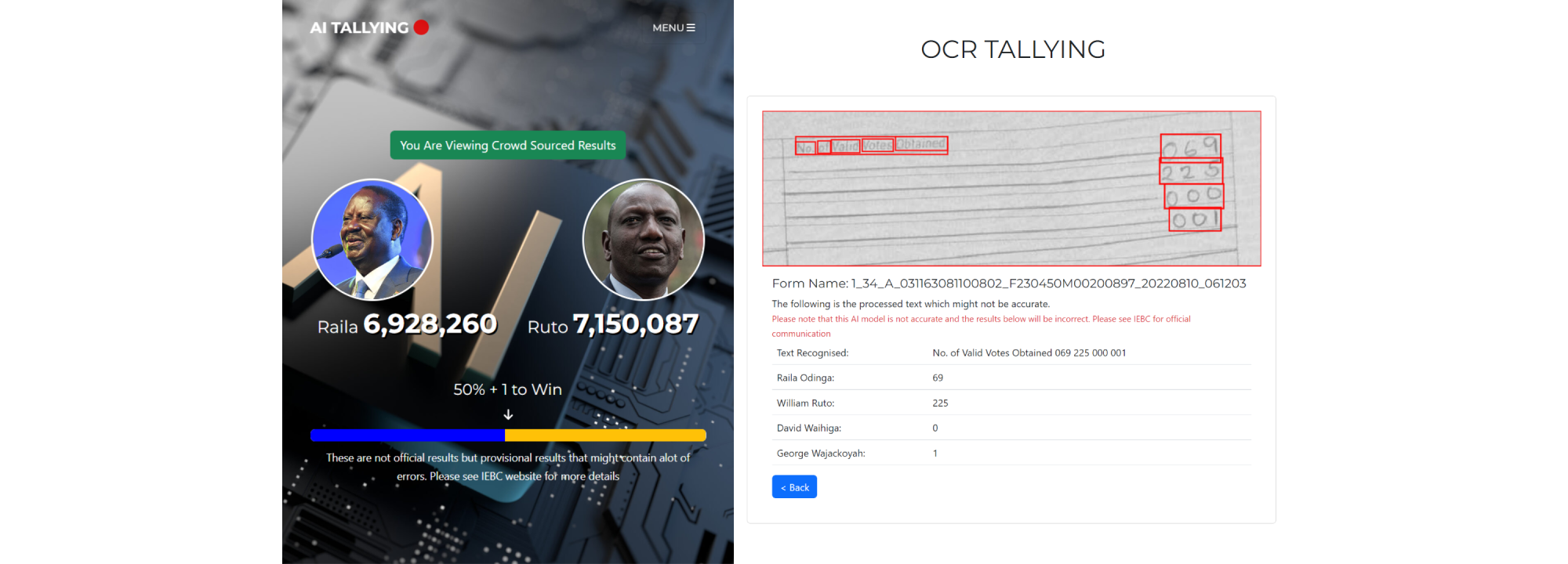
Using AI to verify Kenya Election Results
Introduction
In August 2022, elections were held in Kenya to decide the next leaders, the main one being the presidential elections.
The way elections work is, that there are 46,229 polling centres where elections take place. After the voting period ends (typically around 5pm on election day) the polling station officials commence counting of votes.
They then record the tally manually on a physical form. This form is referred to as Form 34A.
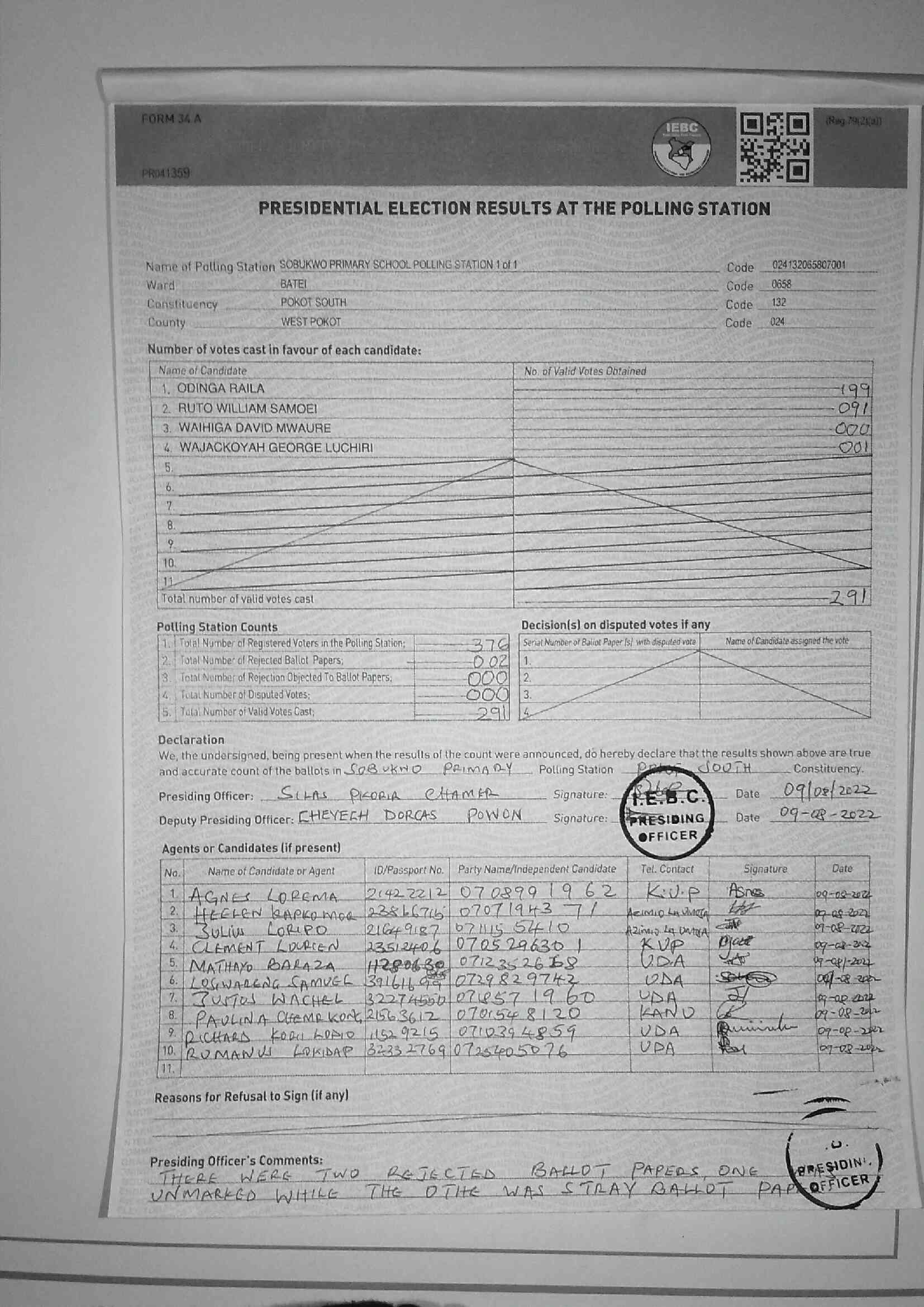
The forms are then uploaded to a public portal where anyone can download and view them. See sample below
This project uses AI to read the Form 34As, extract the tally from the handwritten digits and display the results on a public portal. This was phase one of the project.
As you can already guess, this isn't going to be very accurate and needs some way of validating the AI results. Here comes phase two, to validate the AI's output; I resulted to crowsource the verification of the AI results.
This was done via public facing portal here
Phase One: Using AI to read data from the form
This was probably the hardest part. Firstly I tried feeding the form directly to already trained OCR extractors. I tried both AWS Textract and GCP Document AI but did not get the best results.
The output I was getting was just RAW text with also of "noise" hence extracting the actual numbers from the OCR ouput was really hard.
From the example Form34A above, our area of interest is essentially the top left quadrant with these values:
| ODINGA RAILA | 199 |
| RUTO WILLIAM SAMOEI | 091 |
| WAIHIGA DAVID MWAURE | 000 |
| WAJACKOYAH GEORGE LUCHIRI | 001 |
As you can tell running OCR on the whole form isn't useful as we'll get a bunch of unwanted text "noise" making it harder to extract the final numbers that we want. Here is a sample output
FORM 34 A (Rug.79(2)(a)) IEBC PR041359 PRESIDENTIAL ELECTION RESULTS AT THE POLLING STATION Name of Palling Station SOBUKWO PRIMARY SCHOOL POLLING STATION 1 of 1 Code 024132065807001 Ward BATEI Code 0658 Constituency POKOT SOUTH Code 132 County WEST POKOT Code 024 Number of votes cast in favour of each candidate: Name of Candidate No. of Valid Votes Obtained 1. ODINGA RAILA 199 2. RUTO WILLIAM SAMOEI 091 3. WAIHIGA DAVID MWAURE 000 4. WAJACKOYAH GEORGE LUCHIRI 001 5. 6. 7 8. 9. 10. 11 Total number of valid votes cast 291 Polling Station Counts Decision(s) on disputed votes if any 1. Total Number of Registered Voters in the Polling Station; 376 Seriat Number of Baliot Paper with dispuled vota Name of Candidate assigned the vote 2. Total Number of Rejected Ballot Papers; 002 1. 3 Total Nember of Rejection Objected To Ballot Papers; 000 2. 4 Total Number of Disputed Votes; 000 3. 5. Total Number of Valid Votes Cast; 291 4 Declaration We, the undersigned, being present when the results of the count were announced, do hereby declare that the results shown above are true and accurate count of the ballots in SOBUKNO PRIMA RY Polling Station process SOUTH Constituency. Presiding Officer: SCLAS PICORIR CHAMER Signature: I.E.B.C. Date 09/08/2022 Deputy Presiding Officer: CHEVECH DORCAS POWON Signature: PRESIDING Date 09-08-2022 OFFICER Agents or Candidates (if present) Tel. Contact Signature Date No. Name of Candidate or Agent ID/Passport No. Party Name/Independent Candidate 1. AGNES LOREMA 2142 2212 0708991962 K.U.P Asne 09-08-2024 2. HEELEN KAPKOMOR 23866716 070719437 ACIMID Ln MM H 09 08-2022 3. 071115 5410 a Julius LORIPO 21649187 Azina 4 UNIVA 09-03-2022 4. CLEMENT LOURIEN 23512406 0705296301 KVP gase 09-08-2020 5. MATHAYO BARAZA 11280638 0712352668 UDA to 09-08/-2022 6. LOGWARGNG.SAMUEL 39161699 0729829742 UDA SOME 00/-08-2020 7. 3USTOS WACHEL 32274550 07857 1960 UDA J1 8. 0705548120 KANU 09-08-2022 PAULINA CHEMR KONG 21563612 B Sminish 09-08-2022 9. 1529215 0710394859 UDA 09-08-2020 RICHARD KORU LOPIO 10. RUMANUS LOKIDAP 32332769 0725405076 UPA for 09-08-2022 11. Reasons for Refusal to Sign (if any) Presiding Officer's UNMARKED THERE WHILE THE OTHE WAS STRAY BALLOT OFFICER WERE REJECTED BALLOT Comments: TWO PAPERS, ONE
For this specific form, you could easily use REGEX to extract the numbers, but more often than not the regex expression would not work, since the numbers that we are interested in would appear in different positions in the output of different forms.
So I decided manually crop the image and just feed this section to AWS Textract.

This yielded much better results. The output of this was the following:
No. of Valid Votes Obtained
199
091
000
001
But now here comes the question. How do we crop 46,000 forms?

We could build our own object detection model from scratch (takes a very long time to setup) or we could use a pre-trained one.
YOLO
You Only Live Once , I mean "You only look once" is a state-of-the-art, real-time object detection system. That is extremely fast, it is typically used in for identifying real-world objects, like in Autonomous driving, Security and Surveillance etc.
The basis of how it works, is you give it an image and it gives you a bounding box (coordinates) where it "thinks" the object is found. If you want an in-depth guide on how YOLO works see this video below by Aladdin Persson

Since YOLO is trained to identify real-world objects (cats, dogs, people...), it's not going to work out of the box for our form. We need to retrain it, not from scratch but train it on new information (transfer learning).
For this we are going to use the latest YOLOv5 and another website called makesense.ai . We will be using makesense.ai (an image annotation tool) to create coordinates of our crop region. In my case, I did about 100. (70 for training and 30 for testing)
The way the model is evaluated is based on a simple formula called IoU (Intersection Over Union).
The formula is (Intersection Area) / (Union Area) . In the image below the green box represents our true bounding box and the red represents the AI prediction while training.
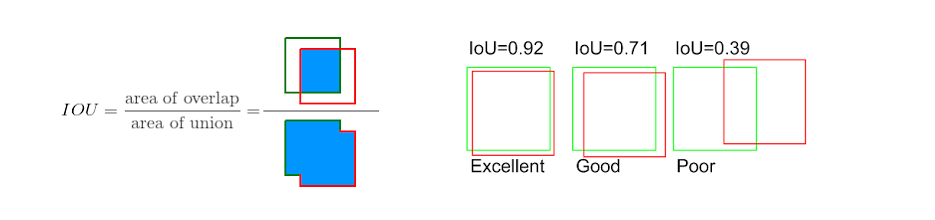
Hence, values the closer the IoU value is to 1, the better.
So after training the model for a while I was able to get an IoU of about 0.9 which is really good.
The next step is to crop the images using the coordinates given. Luckily YOLOv5 has a handy command for doing that. Now that we have the cropped images, we can now feed them to AWS Textract to get the text predictions. Once this was done it was a simple REGEX to get the actual numbers for each candidate and create a tally. When I created the tally I noted that the tally was quite off by a lot, for example, I got a tally in the billions which is not possible. This was due to some text predictions looking like this "No of Obtained Votes 677000001 002", I could try using a better regex expression but there could be a million edge cases, which brings us to phase two.
Phase Two : How to deal with wrong predictions.

We need a way to verify to correct wrong predictions and also fill missing data that might have been missed by the AI. So I decided to create a simple portal to crowdsource the verification part.
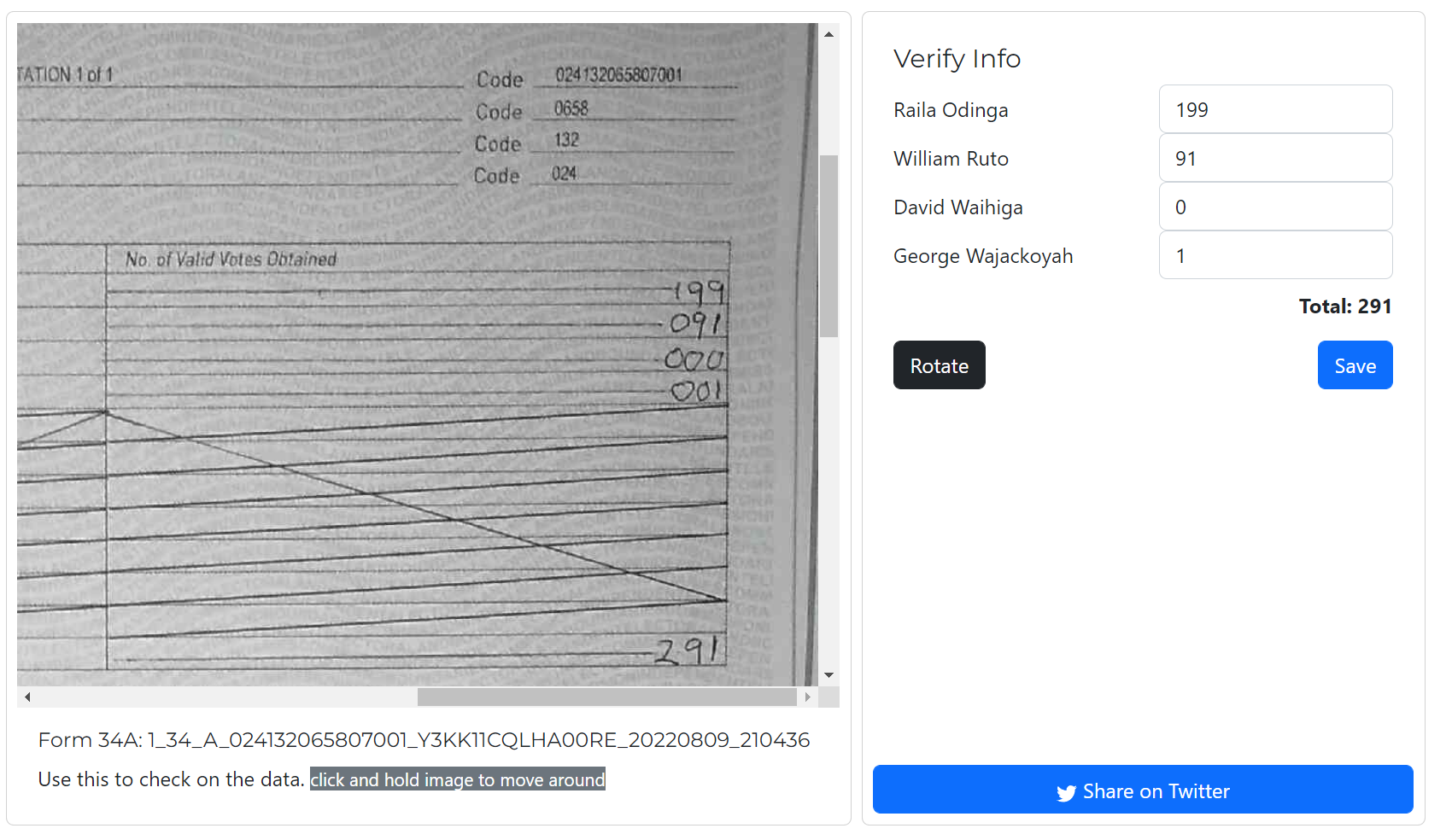
When users submit the form above, the system picks the value with the highest frequency, ensuring that even if someone enters a wrong value, the tally will more or less be accurate since the assumption is that most people are honest
In hindsight, I might as well have started with this phase, and skipped the whole complex AI part. Though, a huge advantage is that during the verification process most of the values are already prefilled, and all that the user has to do is to click the Save/Verified button.
Within a few days, I was able to get about 4,000 users who verified the results.
Findings
About a week after the election day, the results were officially announced and "our results" weren't that far off. Comparing the crowdsourced results vs the official results we had a margin of error of about 0.3-0.4% which is not bad at all. I'm quite grateful to all who participated in the verification.
For the AI OCR vs the crowd-sourced results, I had exact values predicted 97% of the time, also not bad.
What's next? The next election is a bit far, though I have the data available for anyone interested in training a better OCR AI, especially since this whole project was done in hurry(in about 4 days) and had to deliver before the official results were out 😂😂.
If you are interested here is the repo with the data. Your task is to train an AI and see if you can achieve better results. Hoping to see a custom pipeline from downloading images, cropping then OCR. Especially, without using cloud-based solutions for the OCR part. To start you can checkout Keras OCR Captcha model. Create an issue on the repo to share and discuss your results. I have truncated the data to prevent cheating 😂😂. May the best AI win