

Handling a million requests: Part 2 (gRPC)
For Part One see this
In this part we're a going to see how using protobufs and gRPC helps us.
We will be trying to see how many requests our instance can handle per minute and look out for other benefits as well.
To follow along clone this repo stress-testing-app
We are going to spin up a Node.js cluster that servers requests as Protobufs/Protobuffers/Protocol Buffers using gRPC.
Firstly just a quick refresher on what proto buffers are. Protobuffers are a cool way of transmitting data that sort of losslessly-compresses it.
Here is an example:
Assume we had a regular server and this is the JSON response we have to send back:
message User {string username = 1;bool premium = 2;string nextBillingDate = 3;Country country = 4;string port = 5;int32 UUID = 6;}
enum Country {KE = 0;US = 1;UK = 2;AU = 3;JP = 4;DE = 5;}
["Bob", 0, "01-01-2023", 0, 3000, 567]
Demo:
- Clone the repo above.
- Install docker and docker-compose on your machine
- Build the docker images using
bash build.sh
- Start the server using
bash starthttp.sh
Once installed you can run this command to perform the test from the same machine
k6 run http-tests/local.js --duration=60s --vus=32
vus stands for virtual users, you can experiment with this value, based on your hardware you will get different values for RPS (requests per second).
When increasing the number of virtual users you may have to increase the limit on concurrent file descriptors being used by running ulimit -n 250000 this will increase it to 250,000 which you probably won't reach.
To perform the test from another machine, install k6 and clone the repo, then change the REMOTE_GRPC_HOST variable in the config.js file to be where your server is hosted.
k6 run http-tests/remote.js --duration=60s --vus=32
Results
This test was performed on a c5.4xlarge.
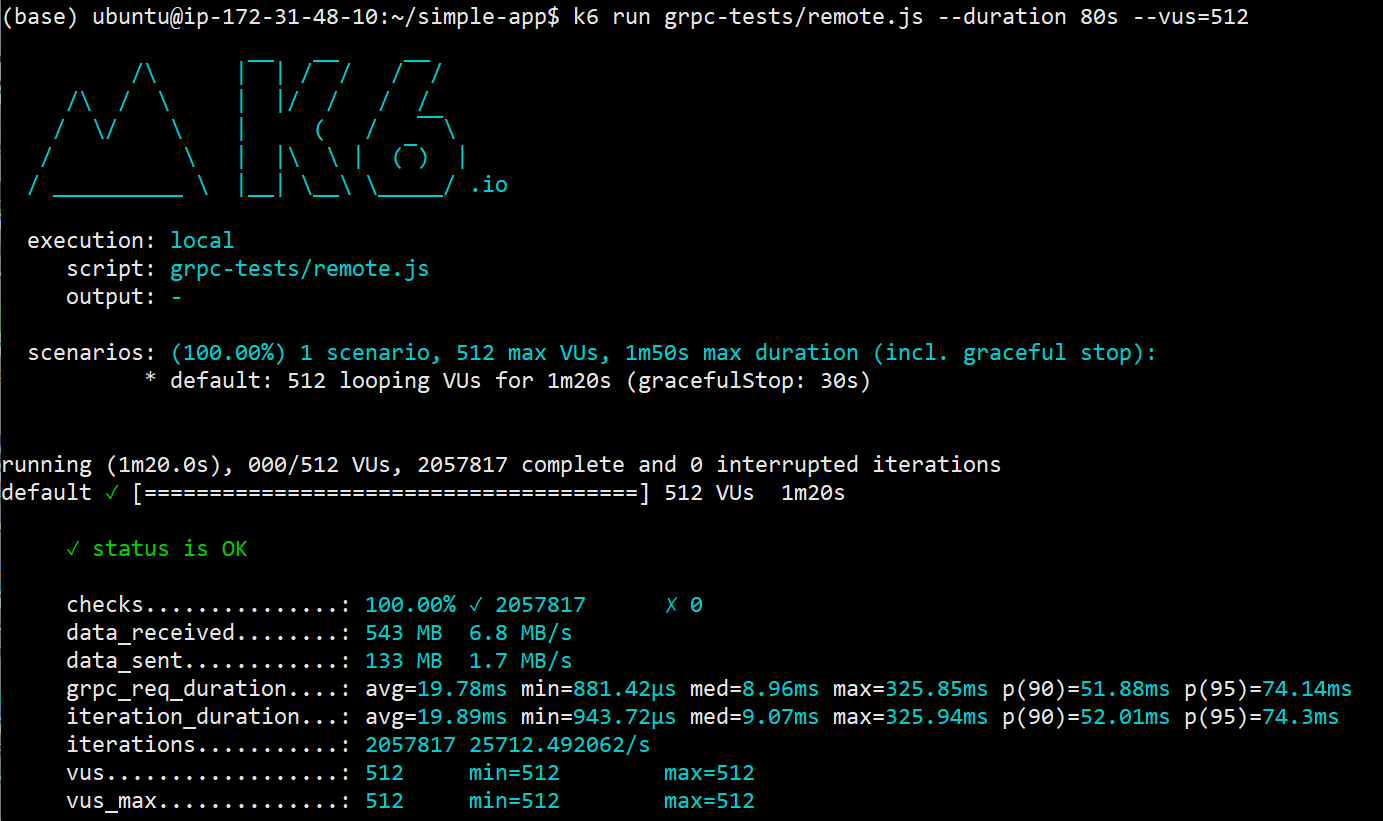
From this test we get about 26K RPS and 1.5 Million Request Per Minute (test was run for 80 seconds). Not too bad, though slightly lower than our first experiment with HTTP, I suppose it had just a tiny overhead with gRPC, but still impressive nonetheless.
The main takeaway is the bandwidth savings, if you compare it to our previous results with HTTP, we had the following
HTTP (2 Million Requests ~ 60secs)
- received: 663 MB
- sent:171 MB
- total:834MB
gRPC (2 Million Requests ~ 80 secs)
- received:543 MB
- sent:133
- total:676MB
Using gRPC and proto buffers we get about a 20% reduction in data usage. This is important for two reasons, the obvious being data transfer costs and secondly getting additional bandwidth like switching from 1Gbps to 10Gbps clusters is sometimes really expensive. It is also worth noting that our response payload is fairly small and simple. Most server responses have multiple nested objects, meaning data savings could be way more than 20%.